コンテナエディターと見出しエディター
先週、xfy Communityがコンテナエディターを紹介してくださいました。
いつも画面イメージをつけてくれるのですが、これはあちらで新たに作られたものですね。素材には一般的な文書を使われていて、中身もしっかり入っています。実際に使う場面に即したスナップショットになっています。ありがとうございました。
なにせ、わたしが付けるスナップは、自分のありあわせの文書を使うので、内容が一般的かというと……ね…。
コンテナエディターと見出しエディター
コンテナエディターと見出しエディター。2つの違いは、同じ文書に両方を適用してみると分かるか、と。
例えば、次の文書(URL)で試してみます:
Softwears
http://www.yamahige.jp/softwares/index.html
# ね、こういうときに、手近な素材に走るんですよね…
- まず見出しエディターを適用します: ボキャブラリーコンポーネントを見出しエディターにします。
- 次ぎに、右ペインにカーソルを置いて、コンテナエディターを適用します。
コンテナエディターの表示設定を次のようにします。「コンテナエディター」メニューから「表示」を選んで、次のように「ラベルに表示する要素名の一部を記号で」と「コンテナと見出しのみを表示」だけにチェック(v)が入るようにします。
- ラベルにクラス名を表示
- v ラベルに表示する要素名の一部を記号で
- ラベルにIDを表示
- ----------
- 選択されたときに属性を表示
- ----------
- v コンテナと見出しのみを表示
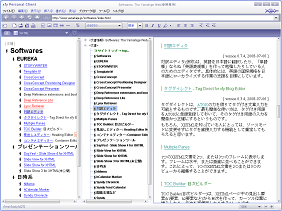
- すると、こんな風に見えます…。
 >>大きい図
>>大きい図
見出しエディターでは、見出しに目次風のインデントがついて表示されます。こんな感じ:
- § Softwears
- § EUREKA
- § STORYWRITER
- § Template It!
コンテナエディターでは、同じ部分がこのように表示されてますね:
- § Softwears
- § EUREKA
- § STORYWRITER
- § Template It!
コンテナ(div要素)は、文書を構成する要素を様々にグルーピングするために使われます。章節構成もその1つでしょう。
しかし、コンテナで章節をグルーピングしなくても、見出しを大きくしたりして区別すれば、人には章節の構成が見えます。ワープロがそうですね。
見出しエディターは、コンテナによるグルーピングにかかわらず、見出しだけに基づいて章節構成を表示し、章の入れ替えなどの編集を可能にしています。上の例の文書は、章節の構成にコンテナを使っていませんが、それにもかかわらず、章節構成をインデントで示しています。
普通はコンテナを使いません、というか知りませんから、見出しエディターだけで十分だと思います。
グルーピング
「章節以外に、どんなグルーピングがあるんだ?」
例えば、ブログの段組や記事(エントリー)はコンテナ(div要素)を使ってグルーピングされています。コンテナ(div要素)なしに、現代のWebはありません。
次の例では、スライド表示する部分を、コンテナを使ってグルーピングしています:
定性的で主観的で個人的な記録を活用するシステムの試作 ~ 時間情報を例に
http://www.yamahige.jp/documents/2008-07-24_SigDD_67/20080725-SigDD-67_v2_20080727.html
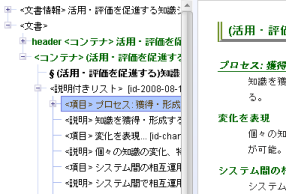
コンテナエディターの表示を次のようにします:
- v ラベルにクラス名を表示
- v ラベルに表示する要素名の一部を記号で
- ラベルにIDを表示
- ----------
- 選択されたときに属性を表示
- ----------
- コンテナと見出しのみを表示
スライド表示する部分は、slideというクラスのコンテナでグルーピングされています。
# 中身がslideというコンテナに属するんですよ、という意味で∋を使ってます。
つづく…
 特に、これという大きな修正はしてません。ただ、自身を2ペインにしたり、見出しの文字が修正できたりと、これまで自分で使ってて、少しずつ溜めてた改善を反映しました。
特に、これという大きな修正はしてません。ただ、自身を2ペインにしたり、見出しの文字が修正できたりと、これまで自分で使ってて、少しずつ溜めてた改善を反映しました。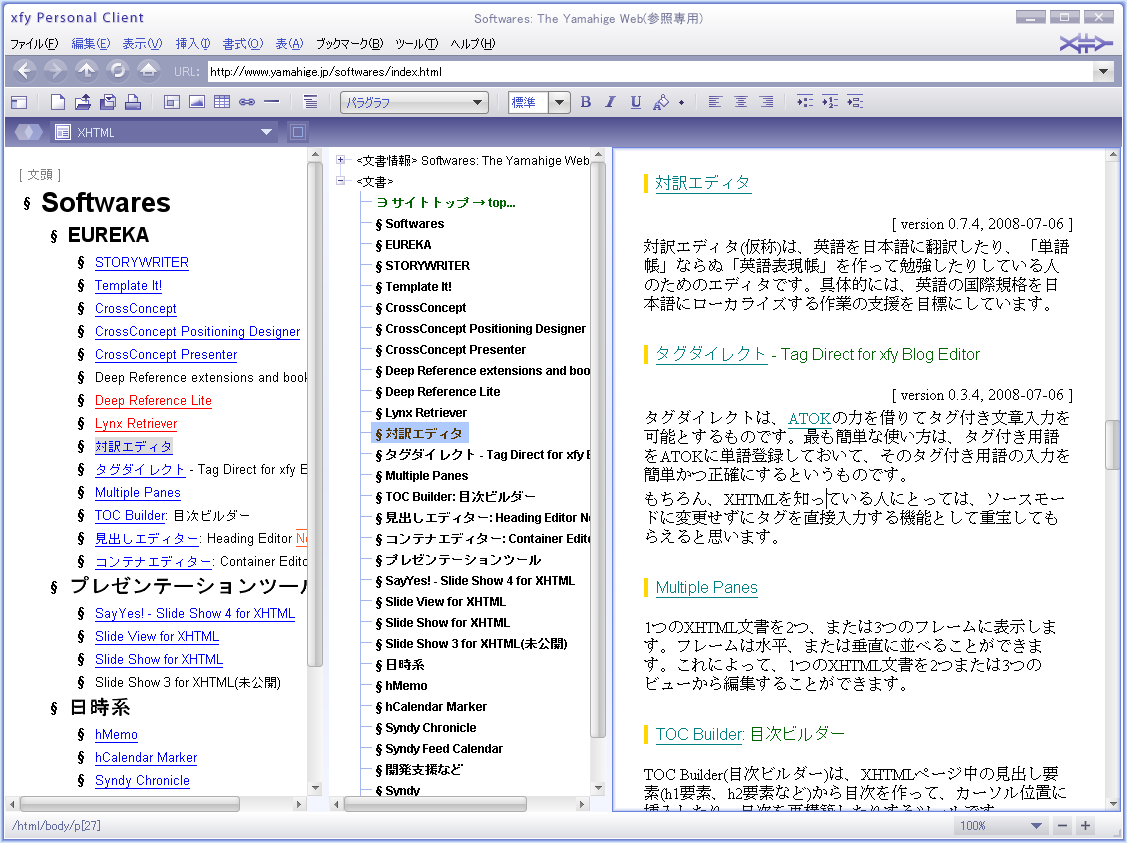{kind=link}